|
 | Барби |
 | Компилятором булочек |
|
| |
Всем привет. Данный сабж довольно сложен для понимания (ввиду моего неумения доходчиво изъясняться), поэтому постараюсь оформить всё в виде небольшой статьи с картинками. Сразу оговорюсь, что всё пока лишь в теории, это проект ещё не существующей системы, а цель темы — получить общественное мнение. Осторожно, многобукаф, слабонервным не читать!
Немножечко введения
Многие из геймеров когда-либо пользовались патчами для локализации игры на язык, отличный от исходного. Стандартный пример - русификатор или дерусификатор. Есть и те, которые заинтересованы в существовании подобных патчей или версий игр. Также имеются и те, кто, собственно, эти патчи и делает.
Так вот, те, кто хоть немного в курсе, как это делается (неважно, на каком уровне), должны понимать, чем перевод игры отличается от перевода произвольного текста. Остальные же вполне могут догадаться.
Давайте попробуем составить примерный список отличий технически-зависимого текста от технически-независимого:
- Служебная информация
Программа — это такая вещь, которой лучше с максимальной точностью объяснять, что ей делать с данными. Поэтому в игровых текстах очень часто присутствует служебная информация, которой в книгах уж точно не встретишь.
- Скриптовая составляющая
Согласитесь, места, в которых должно произойти изменение в выводе текста, легче всего указывать в самом выводимом тексте. Именно поэтому интерактивная система вывода текста довольно популярна: для смены аватарки, воспроизведения звука, запуска следующей сцены и т.п. используются служебные коды. Иногда разработчики идут дальше — интегрируют систему вывода текста и систему игровых событий, т.е. разделения код/текст не существует.
- Форматирование текста
Что же здесь отличного? Ну, например, методы и способы форматирования зависят от конкретной реализации, т.е. стандартным набором жирный/курсив/подчёркнутый дело ограничивается далеко не всегда. Как вам, например, размер окна диалога или позиционирование текста на экране?
- Технические ограничения
Чаще всего игровые тексты имеют определённый набор разрешённых символов, способов форматирования и других характеристик текста (вплоть до длины строки). Любая вольность может просто-напросто поломать игру.
- Предопределённая структура
Главы, параграфы, абзацы - это всё не накладывает жёстких требований к структуре, скорей служит лишь средством для более лёгкого восприятия и разделения по общим признакам. Здесь же текст не идёт одним сплошным полотном, он разбит на атомарные элементы. Атомарность, конечно же, определяется контекстом — в названии предмета это слово или словосочетание, в диалоге это реплика и т.д. и т.п.

Думаю, этого достаточно, чтобы задуматься о сложностях, которые могут возникнуть.
Теперь о главном
Суть такова: я собираюсь писать диплом, и примерное название диплома соответствует заголовку темы (если, конечно, вдруг не решу её внезапно сменить). Так что для меня эта тема актуальна независимо от актуальности для остальных. Но то, чем это в теории будет являться, на самом деле гораздо большее, чем просто VCS.
Я несколько раз брался за реализацию, но дело не идёт, потому что я не могу определиться с архитектурой проекта: постоянно понимаю недостатки текущего варианта и совершенствую модель. Поэтому я решил остановиться, подумать, и проконсультироваться с теми, кого данная тема может заинтересовать.
Итак, мне будут полезны любые адекватные обсуждения на эту тему, любые предложения и мнения людей. Я хочу знать, какие недостатки вы здесь видите, что вы считаете необходимым добавить.
Обращаюсь я, в первую очередь, именно сюда. Почему не на ромхакерские сайты? Скажем так, 4F в этом плане менее специализированный ресурс, здесь больше вероятности получить более ценное мнение, чем мнение дилетанта, набившего руку на переводах Марио и в принципе не способного представить практическую пользу подобных вещей. Также, среди обитающих здесь дилетантов гораздо больше грамотных людей, а многие и вовсе не дилетанты. Я знаю, тут есть и переводчики, и программисты, и просто заинтересованные люди.
Основные требования к поставленной задаче
Рассуждая над основными проблемами, с которыми мне приходилось сталкиваться, я выдвинул следующие требования к будущей системе:
- Гибкость использования
Несмотря на кучу планируемого функционала, архитектура должна позволять выборочно им пользоваться. Т.е. использование данной системы не обязывает делать все операции её средствами, она не должна фактом своего использования накладывать какую-либо монополию.
- Сочетание технического и лингвистического функционала
Технические данные и текст идут бок о бок, и их разделение может быть чревато ошибками. Поэтому всё должно быть в одном месте, но не в одной куче.
- Удобство для всех сторон
Техническая сторона должна по-минимуму сказываться на судьбе переводчика, и наоборот: трудности перевода не должны быть техническими трудностями.
- Максимальное абстрагирование
Универсальность важна везде. Согласитесь, классно, когда одно и то же средство можно применить ко всем случаям. Ну, или почти ко всем.
- Простота и функциональность
Использование системы на базовом уровне не должно требовать от пользователей уметь обращаться с ней в целом на всех уровнях. Пусть порог вхождения определяется особенностями проекта, а не самой системы.
- Неприхотливость к аппаратной платформе
Всё просто: чем больше компьютеров подойдут для использования, тем лучше. Например, я хочу иметь возможность крутить всё это на своём ноутбуке, и я постараюсь избежать препятствующих этому ограничений.
Со средствами разработки я определился (если кому-то интересна техническая сторона вопроса): это C++/Qt, упор на MSVC 9.0 (2008), но с рассчётом на поддержку других компиляторов после небольшого рефакторинга.
Добавлено (через 8 сек.):
Обо всём по порядку
Я перечислю некоторые возможности, которые, как я считаю, должны присутствовать в программе. Всё, что я опишу ниже — не высосано из пальца. Я лишь попытался выделить из своего опыта наиболее острые проблемы, с которыми мне приходилось сталкиваться и хочу охватить как можно больше случаев. Для большего понимания, зачем нужна та или иная возможность, я опишу проблемы, которые сподвигли меня занести эту возможность в список необходимых.
Прошу заметить, список не полон, и содержит лишь то, что пришло мне в голову на момент написания.
Возможность: Контроль версий
Проблема: Сложности организации процесса перевода, необходимость ведения история и откатов изменений.
Пример: Произведены ненужные изменения, потеряны данные, etc.
Решение: Производить контроль версий.
Аналоги: SVN, Git, Dropbox

Возможность: Многопользовательская поддержка
Проблема: Необходимость организации коллективного перевода с централизованным хранилищем.
Пример: Несколько переводчиков переводят одну игру и не могут постоянно иметь актуальные данные.
Решение: Клиент-серверное приложение с возможностью создания централизованного репозитория перевода.
Аналоги: Notabenoid, вышеприведённые системы контроля версий.
Возможность: Распределение прав пользователей
Проблема: Ввиду отсутствия инкапсуляции данных возможны потенциальные ошибки.
Пример: Переводчик случайно задел техническую информацию проекта.
Решение: Создание системы распределения прав доступа.
Возможность: Управление разницей версий перевода
Проблема: Сверение и ведение разных версий перевода требует лишних усилий, приводит к избыточности данных
Пример: Отличия пользовательского интерфейса компьютера, телефона и консоли (нажмите Start / кликните мышью / коснитесь экрана); отличия версий разных регионов, цензура (church / hospital).
Решение: Создание контекстов и диалектов, которые хранят лишь обусловленную ими разницу.
Аналоги: Неизвестны.

Возможность: Глоссарий
Проблема: Переводчик может не учесть, что переводимое им слово есть в утверждённом глоссарии и перевести его по-своему.
Пример: Несколько переводчиков по-разному перевели термин.
Решение: Глоссарий должен быть легко доступен, элементы глоссария должны визуально выделяться на фоне остального текста.
Аналоги: Любое средство хранения списка терминов - MS Excel, OO Calc.

Возможность: Редакторские правки
Проблема: Редактор должен аргументировать и комментировать внесённые изменения, делать пометки; также изменения должны быть видны сразу (зачёркнуто, помечено и т.п.).
Пример: Для дальнейшего перевода необходимо знать причины правок, а редактор в этот момент недоступен.
Решение: Создание системы редактуры с данными возможностями.
Аналоги: Системы код-ревью: Atlassian Crucible; в том же Word'е вроде бы есть такие функции.

Возможность: Удаление дубликатов
Проблема: Дублирование текста приводит к необходимости излишней работы, сулит расхождениями шаблонных текстов.
Пример: В каждом уровне игры повторяется описание одних и тех же предметов.
Решение: Выборочно или полуавтоматически убирать дубликаты, оставляя ссылку на один уникальный элемент.
Аналоги: Память переводов.
Возможность: WYSIWYG-представление тегов форматирования
Проблема: Форматирование текста тегами и кодами ведёт к потенциальным ошибкам, мешает процессу перевода
Пример: %format=bold%Нещадно%resetformat% %image=0x39f7d4dc3199bd0a%отформатированный %pushformat%%format=underlined%тегами%format=italic%текст%popformat%.
Решение: Система представления тегов и кодов форматирования визуально отформатированным «чистым» текстом, т.н. WYSIWYG.
Аналоги: Неизвестны. Например, по отношению к doc или rtf, это MS Word и OO Write; по отношению к HTML какой-нибудь Dreamweaver и т.п.
Возможность: Подсветка синтаксиса
Проблема: Порой визуально очень сложно воспринимать текст с наличием служебной информации.
Пример: См. скриншот ниже.
Решение: Реализовать возможность подсветки синтаксиса.
Аналоги: Notepad++.

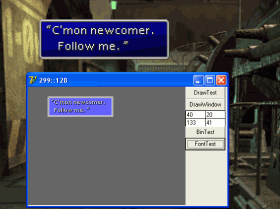
Возможность: Визуализация текста
Проблема: Необходимость подгона текста под размеры предоставленных для его вывода областей в игре.
Пример: В игре нет автоматического переноса текста, приходится вручную подгонять каждую предложение, проверять в игре.
Решение: Система визуализации текста.
 
[ Оригинальный размер (1) ] [ Оригинальный размер (2) ]
Возможность: Списки свойств
Проблема: Связанные с текстом данные приходится хранить отдельно, либо же непосредственно с текстом.
Пример: К тексту привязаны координаты вывода на экран.
Решение: Реализовать систему свойств, позволяющую задать настраиваемые свойства у каждого объекта.
Аналоги: Неизвестны. Подобная система реализована в Qt.

Возможность: Свойства-переменные с определяемой семантикой
Проблема: Часто попадаются данные, которые необходимо менять в зависимости от текста. Это создаёт необходимость создавать дополнительный инструментарий или проверять всё в игре.
Пример: В игре размер диалогового окна задаётся фиксированными значениями.
Решение: Создание системы семантики для свойств. Свойства смогут меняться автоматически при изменении объекта, на который указывает семантика.
Аналоги: Неизвестны. Подобная система реализована в Render Monkey для тестирования шейдеров (predefined variables).
[ Оригинальный размер ]
Возможность: Импорт и экспорт
Проблема: Не каждый захочет использовать данную систему или захочет использовать её частично.
Пример: Кто-нибудь любит переводить в блокноте или Word'е.
Решение: Реализовать систему импорта/экспорта, позволяющую в итоге работать с данными там, где удобно пользователю.
Аналоги: Ммм... даже не знаю, что в данном случае вписать :)
Добавлено (через 14 сек.):
Модель данных
Представляю простую схему текущей модели данных. Это не UML, не реляционная схема, это просто овальчики и стрелочки, для интуитивного понимания.
Одна из возникших на данный момент проблем банальна — я не могу определиться с терминологией, то бишь с именованием элементов данной модели. Поэтому буду писать как текущий вариант наименования, так и альтернативные.

Теперь подробнее:
- Project (Book, Translation) — собственно, проект перевода. Содержит в себе все остальные элементы.
- Context — буквально контекст перевода. Одна из двух вещей для реализации разницы версий перевода.
Здесь остановимся подробнее. Лично у меня это ассоциируется с наследованием в программировании, коллеги поймут почему: ведь контекст, по сути, неявно наследует весь текст каждого языка, и может переопределять элементы и добавлять новые. Думаю, легче будет объяснить на примере.

У нас есть два языка - English и Russian, вроде бы всё просто. Но у нас есть три целевых платформы, некоторые сообщения на которых будут различны независимо от языка (ну, разве что если не попадётся язык, на котором можно одним текстом описать хотя бы два из трёх случаев). Можно было бы просто создать три полных варианта перевода, каждый с платформо-зависимыми отличиями, но тут на помощь приходит контекст, который позволяет просто создать три глобальных (это главное отличие от диалекта) ответвления.
Теперь про глобальность — суть в том, что контекст не зависит от конкретного языка (поэтому на схеме он выше по иерархии). Своим существованием он говорит о том, что каждый язык должен реализовать описанные в нём элементы (переопределённые или добавленные). В описанном примере в каждом из контекстов есть один элемент, который реализован на всех языках.
Вот сейчас пишу это и понимаю один из недостатков текущей модели: независимо от платформы присутствует сообщение о необходимом действии для начала игры. А значит, необходим элемент, по иерархии стоящий выше контекста, и обязывающий все контексты иметь данный элемент текста. Возможно, стоит просто добавить какой-либо глобальный контекст, от которого будут наследоваться все остальные.
- Language — язык. В классическом случае — это именно самые настоящий язык, но по факту им может являться что угодно, любая вещь, на которую можно что-то перевести.
- Volume (Folder, Directory, Partition) — элемент структуры, эквивалент папки.
- List — user-defined список строк. Вспомогательная вещь.
- Chapter (Group) — группа, набор Entry.
- Dialect — вторая вещь для реализации разницы. В отличии от контекста, это уже ответвления непосредственно языка, привязанные конкретно к этому языку. Например, версии перевода — прозаическая и поэтическая (вспоминая эксперименты Dangaard'а). В остальном тот же контекст.
- Entry (Item, StringItem, Prototype, Entity) — пожалуй, это главный герой нашей сказки.
Скажем так, это прототип строки, который существует независимо от языка, а сама строка уже должна быть реализована на каком-либо языке. Реализована — значит должен быть текст, который соответствует этому прототипу.
Эту штуку можно сопоставить с переменной — она одна и характеризуется фиксированным именем, а уже её значение зависит от области применения (язык и прочее, в нашем случае). Прототип может характеризоваться именем, индексом или чем-нибудь ещё. А может ничем не характеризоваться — просто быть и всё (если где-нибудь необходимо просто множество элементов), это уже зависит от конкретного проекта.
- String (Data, StringData, Implementation) — строка, непосредственно текст. Другими словами — реализация прототипа строки.
Можно представить строку в виде следующей функциональной зависимости:
<текст> = String(Entry, Context, Dialect)
При этом обязательные аргументы тут Entry и Dialect (в качестве основного диалекта выступает сам Language), Context использовать необязательно.
Что, чёрт возьми, это будет из себя представлять?
Когда я задумываюсь об этом, клиентская часть мне представляется как подобие IDE с интегрированной системой контроля версий. Назовём это ITE — Integrated Translation Environment, интегрированная среда перевода :) В теории это будет среда, делающая всё для удобства перевода. Как ворд для набора текста или IDE для программирования.
С серверной частью всё гораздо проще - это обычно приложение без графического интерфейса, которое выдаёт и сохраняет данные по запросам клиента. В качестве графической оболочки для управления им можно использовать ту же клиентскую часть, но можно настраивать и ручками, в консоли.
Честно говоря, как эталон графического интерфейса подобных программ у меня в мозгу прочно засел Круптар.
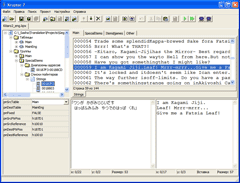
[ Оригинальный размер ]
Это можно заметить и глядя на различные сриншоты визуализаторов выше :) Не стану скрывать, инструментов со схожим интерфейсом мною было написано over 9000.
Я не говорю, что буду копировать. Я лишь сделаю схожую идею интерфейса — будет дерево проекта, будет список строк, будут окошки с текстом. Но это будет гибко, настраиваемо, клонируемо. Можно открыть сколько угодно окон для любого количества языков/строк, расположить их как угодно, привязать к каким угодно спискам (по клику на элементе привязанного списка меняется текст в текстовом поле). Но у истоков стоят такие же базовые элементы - дерево, список, текстовое поле.
Но я постараюсь свести к минимуму необходимость использования элементов навигации. Постараюсь сделать так, чтобы вообще не было необходимости касаться мыши (а тогда можно будет скрыть с экрана лишние элементы управления). Примером тому может послужить Visual Assist X для Microsoft Visual Studio — почти вся навигация там осуществляется в доли секунды посредством удобных горячих клавиш и ввода пары ключевых слов. Мне нравится эта идея, это чертовски удобно.
В прочем, я всё это пишу, чтобы услышать ваше мнение на этот счёт. Так что это всё не принятые решения, а лишь планируемые варианты.
Я набросал такой вот макет:

[ Оригинальный размер ]
Не стоит пугаться, это лишь голый макет возможного расположения элементов, ничего общего с реальностью он не имеет. Хотя проблема размещения элементов на экране тут ещё как актуальна. Тем, кто использует два монитора, повезло — это в два раза удобней, чем использовать один монитор (мои личные выводы после подобной практики). Но вот расположить всё необходимое на экране одного монитора (особенно на экране ноутбука) — это сущий ад, поэтому надо подумать об автоматически скрываемых элементах.
Итого: что я хочу вынести на обсуждение
- Восприятие: какие моменты слишком непонятны, что лишнее, что вообще как китайская грамота?
- Идея: ваше отношение к идее, концепции?
- Востребованность: насколько актуален и востребован проект?
- Возможности: что лишнее, чего не хватает, что непонятно?
- Модель: адекватность, недостатки структуры?
- Терминология: как называть элементы модели данных?
- Интерфейс: каким он должен быть?
- Помощь: есть ли те, кто хочет и может помочь в разработке?
|
|









